

At VDA we like to tackle many different types of security challenges – one of them being Application Security (AppSec). A recent project involves working with the Microsoft Security Risk Detection (MSRD) fuzzing platform. In basic terms, MSRD is a security discovery platform that can be used on many different applications. In a separate blog, we demonstrate how to write a fuzzing harness. For purposes of this blog, we decided to target some PDF reader applications – one of them being VeryPDF Reader. Our goal for this project was to show that MSRD can easily be used to find important bugs in software: in this case, an exploitable bug that can be used to get code execution or escalated privileges on the machine running the application. The hardest part of achieving this goal is finding a bug that provides you with the correct scenario that allows for code execution. With this goal in mind, we are going to discuss the steps taken to locate and determine if the bugs we found are exploitable.
This blog post will have two parts. Part 1 will focus on how we went about discovering a crash. Part 2 will focus on determining if the crash is exploitable, and further building an exploit for Windows 10.
Action items Covered in Part 1:
- Picking the Target
- Finding Seeds
- Fuzzing the Target
- Crashes and More Crashes
- Analysis and Debugging
Picking the Target
For this step, the goal is to identify an application that we can fuzz with success. Some questions that need to be asked are: How is a bug going to be used? Are we just going to report crashes to a dev team or create an exploit for the bug? (We always contact the vendor first — CVE-2019-11493 for this exploit.) As an example for this blog post, we picked VeryPDF Reader because it’s not as popular as Adobe, but is used heavily in the business industry and has a trial available, which means there is a potential that some future clients would be using it.
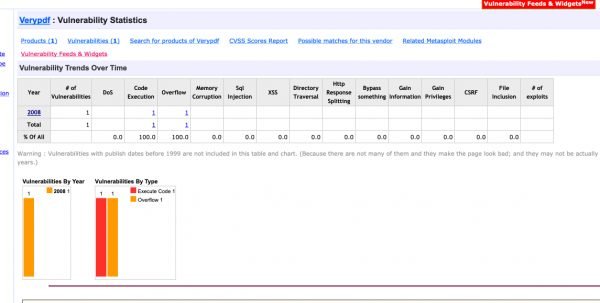
One good way to learn how much a target application has been exploited is to look at assigned CVE’s from past years. This will give you a good determination on how much testing was done to your target application and how easy or hard it might be to find exploitable bugs.
By visiting VeryPDF Editor CVE’s and looking at the number of CVE’s assigned, we saw only 1 from 2008. We considered this to indicate that some good crashes, which could possibly turn into code execution were not yet identified. Most PDF readers have many more CVE’s.
Finding Seeds
Upon figuring out a good target, next we identified what file types were supported and how VeryPDF Editor used them. VeryPDF Editor supported multiple file types, but since the application has not been tested as heavily as Adobe or others, we stuck with the PDF format and created seeds based on that.
To build the seeds we investigated the different PDF file types and what VeryPDF Reader supported. It seemed JavaScript was out of the question as there was little or no support, so we switched over to images that could be converted to PDF’s using various online converters and other software that was free. This allowed us to not just have the same PDF’s with the same formatting, but all different types of formatting from different applications that were able to create PDF documents. During this we found that VeryPDF Editor was not able to open some converted image files when converted by different software. This gave us hope that finding bugs in images to PDF would provide good results. Overall our list of different PDF format types included:
- Signed PDF’s
- PDF Annotations and Comments
With the formats chosen and seeds gathered from various different ways we were ready to start fuzzing the target application. As a side note, If you are not able to find any examples of file types that your target application supports try using a Google dork extension to find your seed files. This helped us find uncommon files and formats.
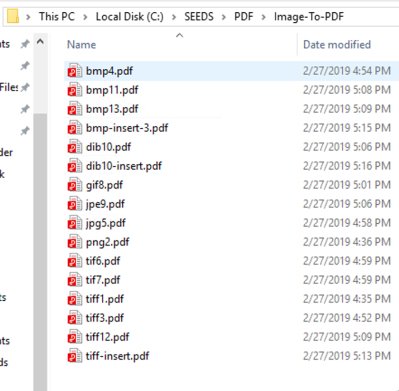
Below are some examples of image files converted to PDF that were used to fuzz VeryPDF Editor.
Fuzzing the Target
Documentation for setting up a MSRD job is publicly available on the web. For this blog, we are going to skip those steps. Understanding what you are fuzzing and how the file format works is extremely important. For example, PDF’s can be compressed and encoded using many different methods. It took time to learn the PDF format and other details, like decoding of PDF documents and trimming the document down to allow for a better method of finding bugs once a crash is found.
Here we can see the job that was started with the Seed file types as mentioned above. MSRD found 149 issues or crashes.
![]()
The runtime for MSRD was 14 days. Next we will dig into the results of what MSRD found and and start analyzing crashes.
Crashes and More Crashes
After about a week of running MSRD against our target, we found some crashes that looked interesting. The different PDF formats submitted have caused many crashes once mutated. Overall, this provided some great data to start digging into and investigating.
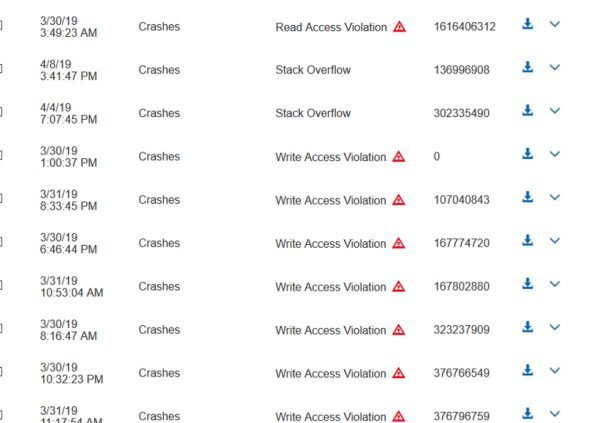
At this point, we began looking for Access Violations that caused the application to crash. Many Write and Read access violations were found.
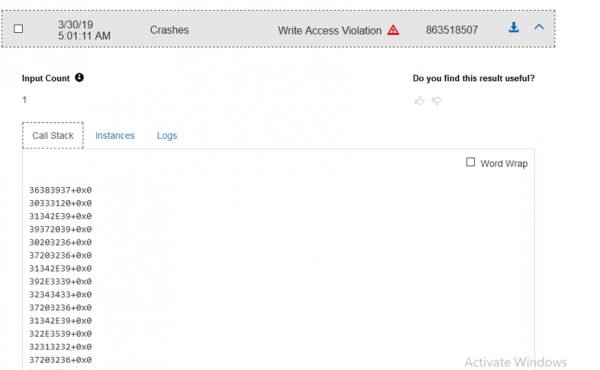
When looking at crashes in MSRD we were able to see the call stack, what instance caused the crash, and the log information for Windbg. This was really helpful in determining what we were looking at and if a given crash should be investigated further. When looking at the log information we saw what exception was thrown and usually the call stack, depending on the particular crash. In this example we saw a Write Access Violation, which caused the call stack to look weird. Usually we get some symbols, but this time we were seeing a complete overwrite of the stack. This would seemed to indicate that we found a memory overflow in VeryPDF Editor. This can be partially determined by looking at the logs and the call stack, but we did not know for sure until the crash files were downloaded and manually investigated with a debugger.
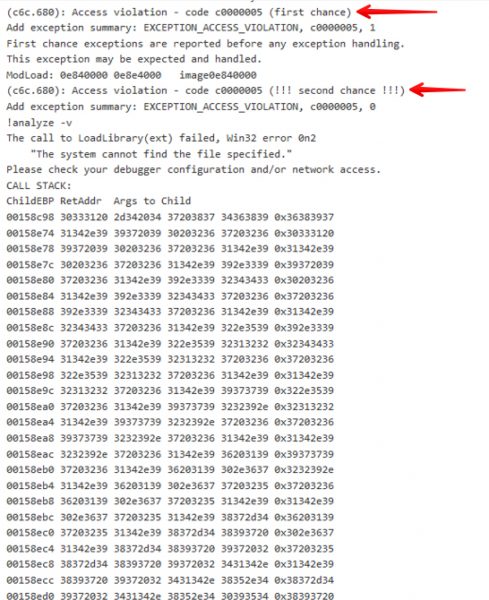
Next we looked at the Windbg log on MSRD, which showed us what commands were run, and was helpful to determine why the crash was listed as a Write Access Violation. Below we can see that the MSRD fuzzer hit a second chance Access Violation, Which is not able to continue. This is great as we know we had a good starting point.
Next we started to uncover what was causing the crash and start to do some more digging. We download the seed that caused the crash and installed the application on a test machine to begin further analysis.
Analysis and Debugging
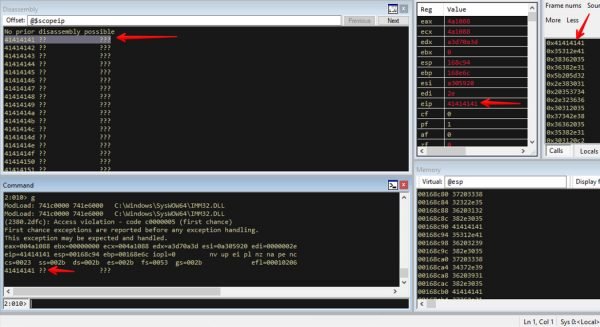
At this point we had investigated the crash and determined that an EIP overwrite of the stack occurred. We have notified the vendor and will wait to release any further information until the vendor has reached back out or a reasonable amount of time passes.
This screen capture demonstrates the EIP register being overwritten with ASCII A’s. This exploitable crash was caused by an MSRD mutated PDF document.